How to build a simple web-based voice bot with api.ai
July 10, 2017
March 2020 update: I used to host an online functional demo version of this project, but this is no longer available. The code remains available as an educational resource.
February 2019 update: I have updated the demo to work with DialogFlow API v2. See a post about the update.
I recently made a prototype voice bot with api.ai. It doesn’t do anything massively useful, but it was interesting for me to figure out what goes into the whole process of making a voice bot, how to think about the interaction model, and what are the related services.
Here’s the code in Github. It works with Chrome on desktop and Android. You can ask it silly things like “what does the fox say,” and it also does simple integer math: you can ask it “what is twelve plus seven”. (Update March 2020: the online demo is no longer available. The code remains available as an educational resource.)
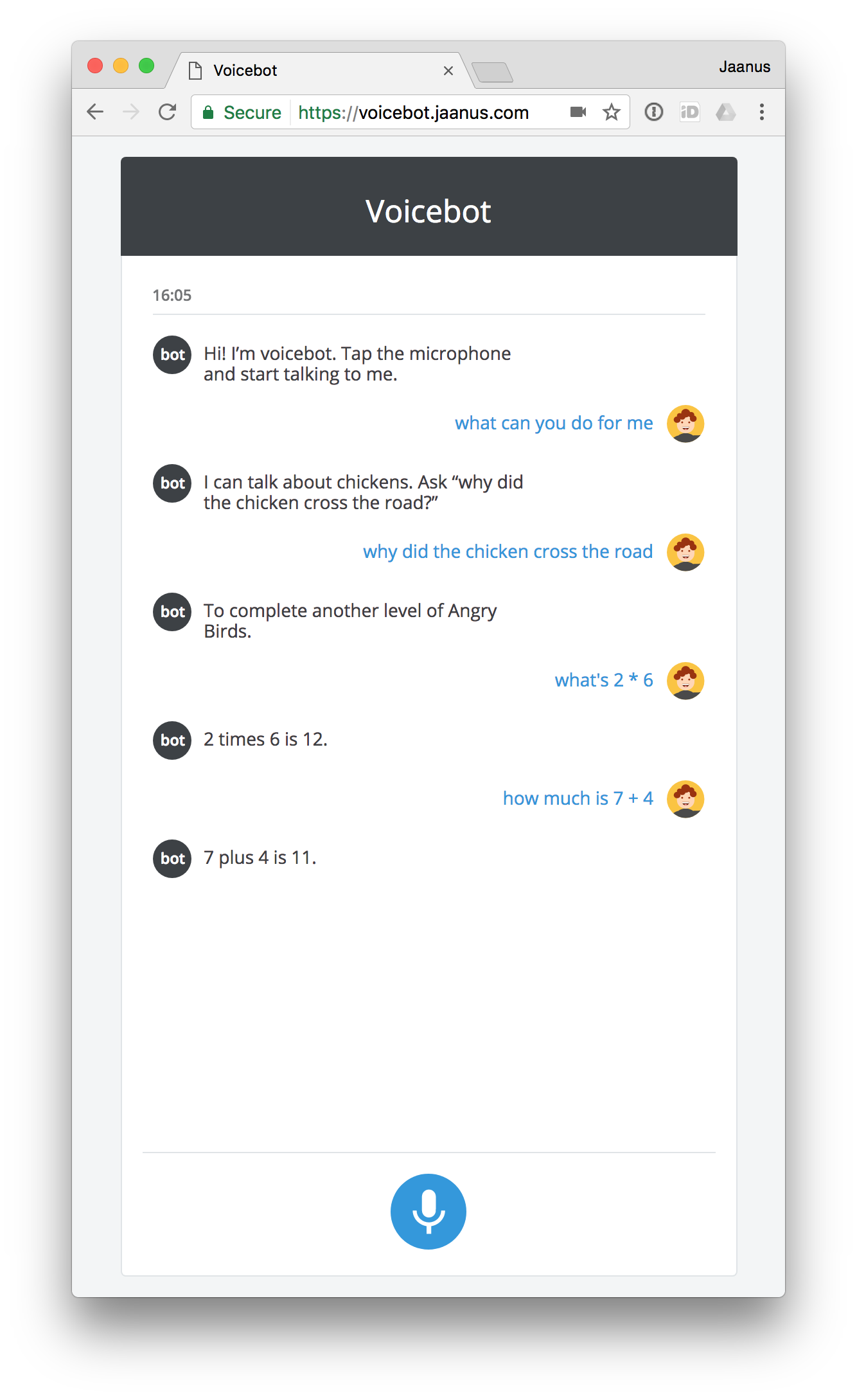
The rest of this post is a discussion on how to make a voice bot quickly and efficiently. I don’t claim to have done exhaustive research on all the options: rather, my focus was on picking the first satisfactory tools I could find, and get something up and running with the least effort.
Interaction model
Although the backend and guts of bots can be complex, the user interaction is very simple: it is a linear dialog. You ask something, the bot responds, and the cycle continues. On a high level, there’s thus no difference between voice and text messaging bots, other than the user’s mode of interacting with it (typing vs talking). Most voice bots also replicate the voice dialog with visual confirmation of the request and response texts (except, of course, when there’s no visual interface available at all, like the dedicated voice devices that are now coming out.)
So, we can split building the voice bot into two parts: what’s the actual user interface to end users, and what handles the backend and logic.
Components
For backend and logic, look no further than api.ai. They claim to be a conversational UX platform enabling brand unique, natural language interactions for devices, applications, and services” and let me “build delightful and natural conversational experiences.” Indeed, that’s what their product does (for free). They’re a startup acquired by Google in late 2016, which tells you a bit about their credibility (anything that Google does in the AI space is worth for me paying attention to.)
I initially thought api.ai can help me with the “voice” part of “voice bot” as well, but no—they basically only do the “bot” part (and do it well.) They expect text as input, and give you text as output, with many additional features, but direct text-to-speech and speech-to-text is not among them. So I had to find a way to do the voice part outside api.ai. (Which could then talk to api.ai with one of their many SDK-s.)
My requirements were to be able to ship a prototype to remote users for testing on both mobile and desktop platforms, to have quick turnaround times and no gates or approvals, and have complete control of the UI—which ruled out doing anything native on mobile app stores for the time being. It also ruled out using api.ai’s web testing console which works kind of nicely on desktop, but not so much on mobile. Building a Google Assistant integration would have been nice, but this would need me to publish a service and get it approved.
Long story short, turns out that the Web Speech API-s in Chrome are in sufficiently usable state for building the text-to-speech and speech-to-text parts. In my testing in April 2017, it appears that Chrome is the only browser who has these API-s available in production version. There isn’t much material and guides available: this one (from 2013!) was the most useful one.
So, I ended up building a simple web app which captures user voice from the browser, sends the recognized text to api.ai, gets the response, shows/talks it to user, and repeats the cycle. Both the speech API-s and api.ai interface were sufficiently high level that the resulting app is quite manageable, and it only took me a few hours to put the initial version together.

Backend
I just created a simple backend in api.ai. For some dialogs like “why did the chicken cross the road”, I just used their default components. I also wanted to something more interesting, though, which is to have actual logic based on the things that the user says. Here’s what building that part looks like.

api.ai has nice tools for extracting parameter values out of what the user says, but as far as I can tell, it doesn’t have any built-in features to create logic based on those parameters. It does let you integrate with an external web service, though, so that’s what I did: I built a simple web service for doing math. api.ai extracts two numbers and an operation between them from the user’s utterance, and then ships it over to my web service, which does the math, returns the result, which api.ai ships back to the user’s browser, which then speaks it. Great stuff.
api.ai has many features which I didn’t look at, like being able to carry over context across the whole conversation, so if you in some later utterance, refer to “this” or “that” or “them,” the system would know what you are talking about. Those would definitely be handy in building a real bot.
Frontend
The frontend is a simple web app which talks to Chrome’s speech API-s on one hand, and api.ai’s Javascript API on the other hand, and just proxies between them. Here’s the conceptual state machine.

One thing to note from the Google article:
Pages hosted on HTTPS do not need to ask repeatedly for permission, whereas HTTP hosted pages do.
So, in order to not get repeated permission prompts, run it over HTTPS, as I do in my demo.
The voice prompts are different on mobile and desktop. On desktop, the browser is silent, whereas on Android the Chrome browser plays quite nice sounds when the voice input starts and ends, so it feels in some sense like a more wholesome interaction on Android.
Summary
I was glad to discover api.ai and the web speech API-s that let me interact with extremely high-level API-s to tip my toe in the voice bots world with quite little effort. I’m sure there are other backend providers available, but api.ai completely met my needs for poking around on this level.
As the platform wars continue into the new voice and assistant domain, I’m sure the tools will continue to evolve. Will we see a similar thing on mobile voice platforms as we currently do on mobile visual interfaces, where Google and Apple try to lock you in to their ecosystem with their own tools? I haven’t yet seen anything this simple for building Siri apps, but it will come eventually.